昨天提到的大型語言模型(LLM)依賴一個非常關鍵的技術架構——Transformer。它在自然語言處理(NLP)領域掀起了革命性的改變,讓語言生成和理解任務中提供了極大的效能提升。今天就讓我們一起來了解這個強大的模型架構吧!
Transformer 是一種基於 自注意力機制(Self-Attention Mechanism) 的神經網路架構,由 Google 在 2017 年提出。它的目標是有效地處理序列資料(如文字、時間序列數據),特別擅長應對長距離相依性問題。這讓它在翻譯、對話生成、文本分類等任務中表現出色。
還記得在介紹RNN的時候是不是有提到傳統的遞迴式神經網路(RNN)在處理長序列資料時,依賴於逐步計算序列中每個元素之間的相依關係,這樣的設計不僅會導致訊息遺失,也難以捕捉長期依賴性。而且RNN必須按序列的順序進行運算,無法進行平行計算,效率比較低。
至於甚麼是Self-Attention Mechanism呢?我留到明天接續補充~
同樣都是為了解決傳統 RNN 在處理長序列時會丟失長距離依賴信息的問題。不過,它們在結構和解決問題的方式上有很大的不同。
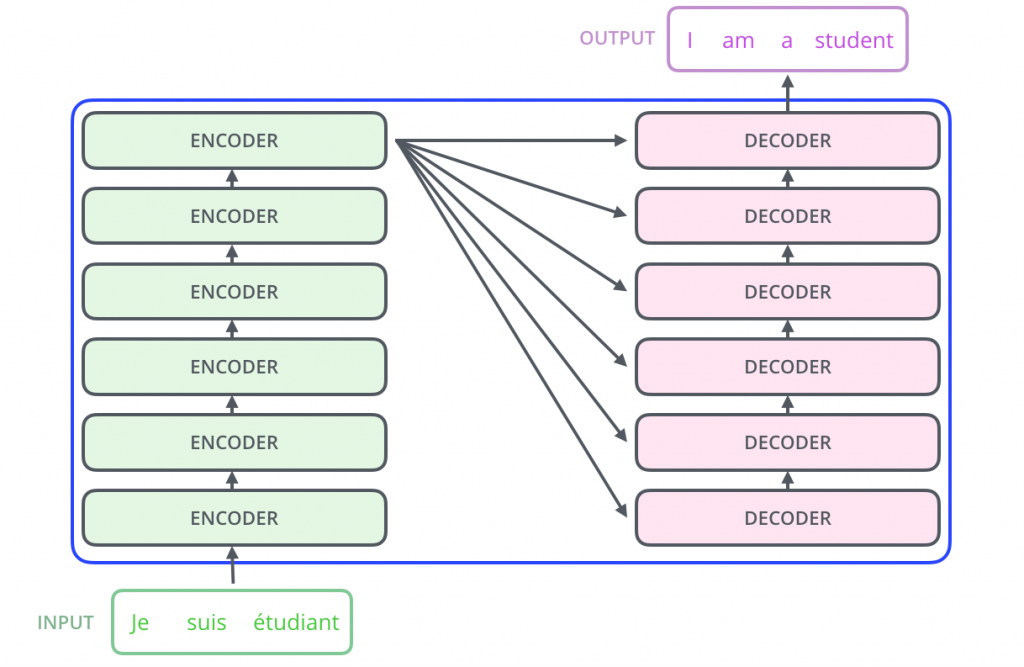
首先來看看Transformer的架構圖:
Transformer 完全基於自注意力機制(Self-Attention Mechanism),摒棄了循環結構,使用多頭自注意力和前饋神經網絡來處理輸入和輸出序列。
但LSTM 是RNN的變形,透過輸入門、遺忘門和輸出門來控制訊息的流動,以此來達到有效捕捉長期依賴關係。
在上面的架構圖可以注意到Transformer的架構,主要由兩個部分組成:編碼器(Encoder) 和 解碼器(Decoder)
編碼器部分(左側)
解碼器部分(右側)
Transformer 在解決長距依賴和序列計算效率方面,對比 RNN 和 LSTM 具有顯著優勢。它通過自注意力機制能夠同時處理整個序列,並能捕捉到每個位置之間的依賴關係,極大提高了模型在處理長序列和大數據集上的表現。
簡單舉個例子來讓大家更好理解。
在前面的介紹中,我們能發現雖然Transformer很厲害,但在厲害的背後也代表它需要大量計算資源,特別是在處理超大模型時,訓練成本是非常高的,因此顯而易見的他的缺點就是高運算成本。
其次,Transformer的表現與訓練資料量成正比,通常需要超大量的資料來訓練模型,否則模型可能會出現過擬合或泛化能力不足的問題,所以需要大量資料也是他的一個問題。
今天接著昨天的LLM講解了Transformer,這個技術是現代 NLP 領域不可或缺的技術,它大大提高了語言模型的效能與應用範圍。今天的介紹幫助大家更好地理解這個關鍵架構。明天我們可以進一步討論。
大家明天見!

